Overview
A somewhat realistic and nice looking flocking simulation can be achieved using three simple behavior rulses for agents:
- Move towards the centroid of your neighbors
- Don't get to close to your neighbors
- Move at a similar speed to your neighbors
By adjusting the radius for which other agents are consider neighbors and the strength of the influence neighbors have your a boid's velocity, some varied and jcomplex behaviors can emmerge.
The main place for optimization is when determining which other agenst should effect the current agent. The naive approach is to simply check every single agent to see if they are within a certain distance. This ofcourse is alot of checks, and doesn't scale well as the number of boids increases (see graphs below). For better results, we implemented a spacial grid so that rather than checking every single other agent, we just need to check the one in our current agent's cell and the 26 neighboring cells. Additionally we can even further optimize this by structuring our data in a way which allows for easy and quicker memory acessing on the GPU. Further analysis on the optimizations below:
Results
These were all run with the coherent grid implementation.
Bird Counts
Parameters
Parameter Set B
Parameter Set C
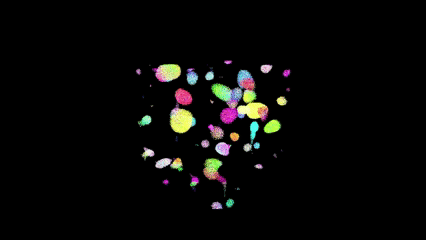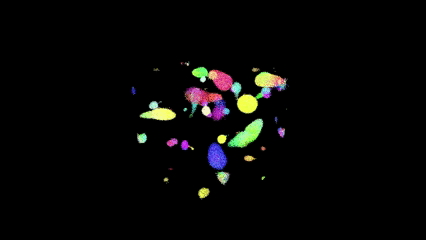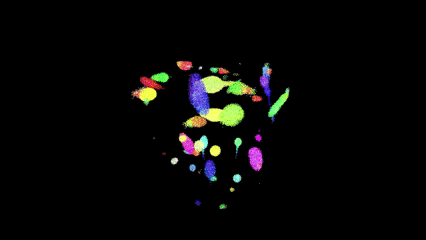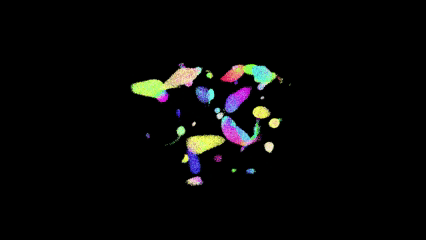
Performance Results
The average fps was calculated over a 10 second window for each simulation method with varying numbers of boids.
FPS Comparisons
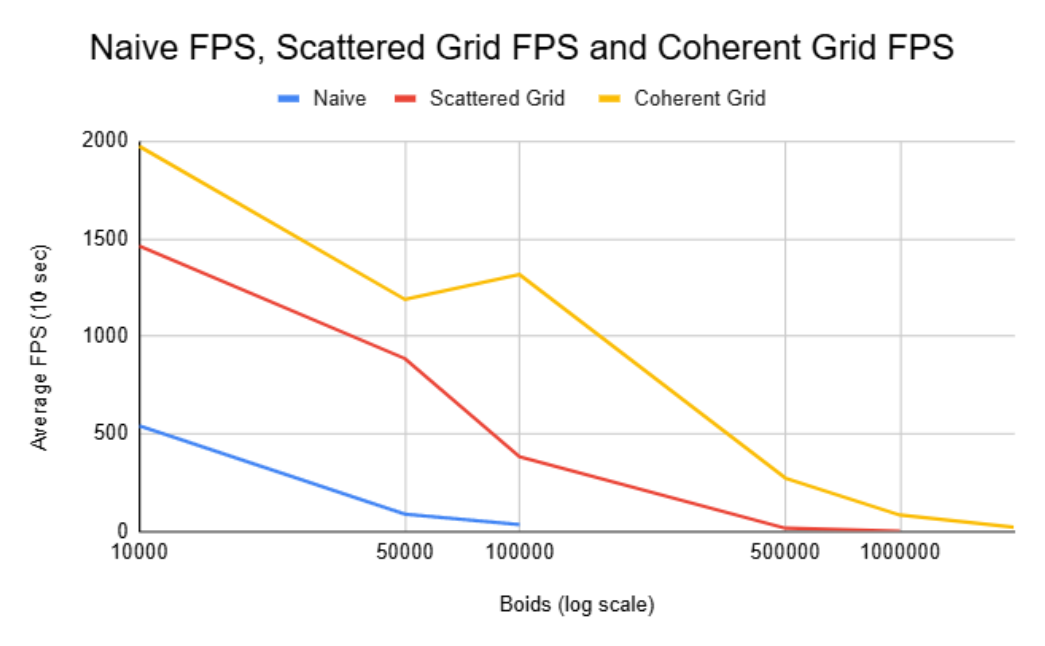
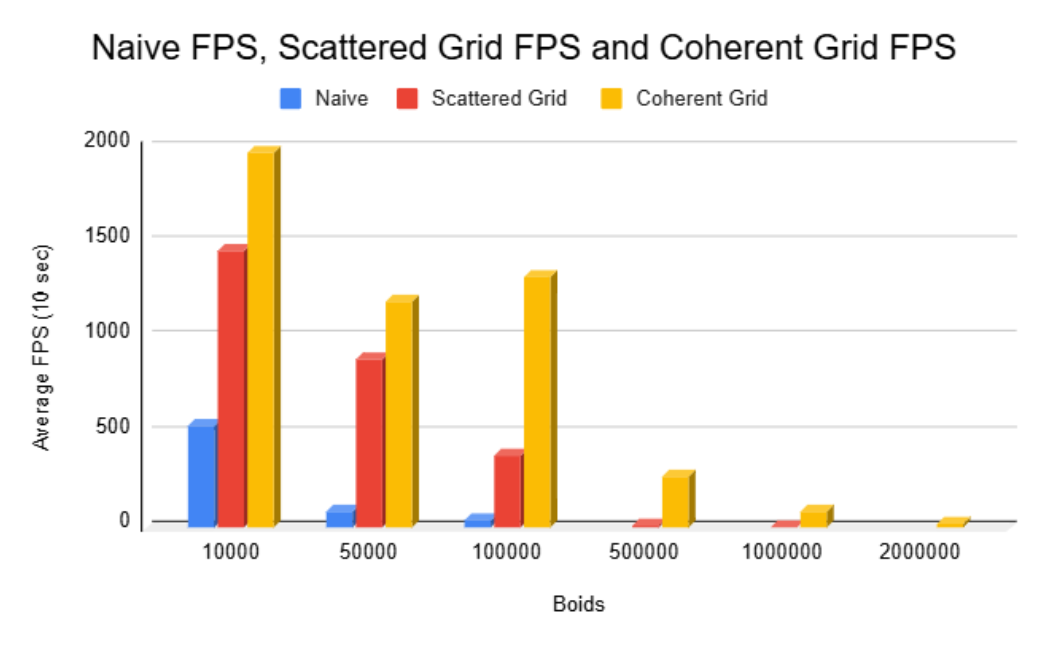
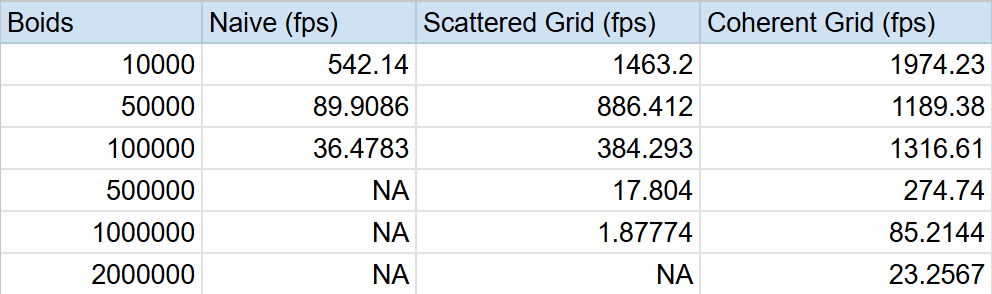
At 1M+ boids, only the coherent grid remains practical.
Performance Analysis
As expected, and as can be seen from the graphs, with the naive implementation, increacing the number of boids dramatically decrease fps. This is because its takes roughly O(N^2) to compare every boid to every other boid. On the other hand, using the grid methods, asumming boids are randomly and somewhat evenly scattered throughout our domain, each boid only need to check the limited number of other boids in the surrouning cells. This of course will be just like the naive case as N really grows, but it allows for a much larger total number to be simulated before a significant and visual decrease in performance.
At first, it seems that changing from organizing the position and velocity data in arbitrary spots to be coherent in memory wouldn't really have any improvements. You are still doing the same number of memory acesses and calculations, and infact a decrease in performance might be expected since we do some additional reorganizing steps. However, as the results show, clearly there was significant improvements when switching to a coherent structure. This is because although we do the same numeber of memory acesses, the cost for each acess is less. Since our memory is coherent, when fetching data for boid i, boid i+1's data is right next to it in memory and thus as we iterate through i, we can "grab" larger chunks of memory at a time.
In order to check 8 blocks instead of 27, you need to double the block size. Thus the total volume of cells actually is less for a 27 cell setup ((3*cellWidth)^3 vs (4*cellWidth)^3). This is somewhat insignificant unless you have a large number of boids, but does technically provide some improvement.